

Customized Training for Text Models
This workflow describes the technical process for creating and training an optimized text model, the LoraDB Edit Caption Model, to generate high-quality, customized captions specific for LoRA Training. It also includes the integration of the model into the LoRaDBEdit software, with advanced features for managing datasets.
Objective
Phase 1: Dataset Creation and Structuring
To ensure effective training, I created a dataset of 1080 images, evenly distributed across various categories to avoid imbalances and ensure sufficient variety in the data.
Image Distribution:
Nature: 130 images
Cities and Architecture: 120 images
People: 130 images
Animals: 130 images
Food and Beverages: 100 images
Technology: 80 images
Fashion and Style: 70 images
Art and Creativity: 70 images
Sports and Physical Activities: 50 images
Travel and Destinations: 50 images
Events and Celebrations: 20 images
Objects and Still Life: 150 images
For each image, I used Florence2Run to generate detailed descriptions, which served as the foundation for creating customized captions specific for LoRA Training.
Phase 2: Caption Creation
From the initial descriptions, I manually created tailored captions for each image. These captions were designed to be concise, descriptive, and relevant, optimizing the model's ability to generate contextualized responses.


Phase 3: Formatting and Organizing the Dataset in CSV
After creating all the captions, I structured the data into a CSV file with two main columns:
• User: The input prompt provided by the user (generated description).
• Prompt: The tailored caption created for LoRA Training (ideal result).
Cleaning and Formatting Phase
Removing Duplicate Data: I eliminated any duplicate descriptions or captions that could negatively affect training.
Completeness Check: I checked that each image had an associated description and caption. If not, I manually corrected the incomplete rows.
Consistent Formatting: I standardized the text format, applying rules such as: • Removing unnecessary spaces at the beginning or end of the text. • Using capital letters to start each sentence. • Adding missing punctuation (e.g., periods at the end).
Dataset Conversion: I saved the dataset in CSV format, ensuring compatibility with the libraries used during training (e.g., pandas for Python).


Preparation for Training
Before the training, I converted the dataset into a JSON structure to make it compatible with the format required by the model:


Phase 4: Model Training
The training was performed using the LLaMA 3.2 model, with 14 billion parameters, leveraging libraries such as Torch for managing and loading the model.
Techniques Used
• LoRA (Low-Rank Adaptation): I used this technique to add only a small number of weights to the main model, reducing computation time and cost.
• Monitoring Training Loss: I tracked the decrease in loss during the training, ensuring it dropped from high values (e.g., 2.89) to lower values (e.g., 0.89), indicating effective learning.
The result was the LoraDB Edit Caption Model, capable of autonomously generating optimized captions for LoRA Training.
Phase 5: Comparison Before and After Training
After completing the training, I observed a significant improvement in the model's responses. Initially, the model tended to generate vague or poorly contextualized responses. Here is an example of a comparison between the responses before and after training:
Before Training:
After Training (with the new model):




This improvement shows how training enabled the model to produce more accurate, descriptive, and contextualized responses, optimizing the generation of customized captions for LoRA Training.
Phase 6: Model Integration into LoRaDBEdit
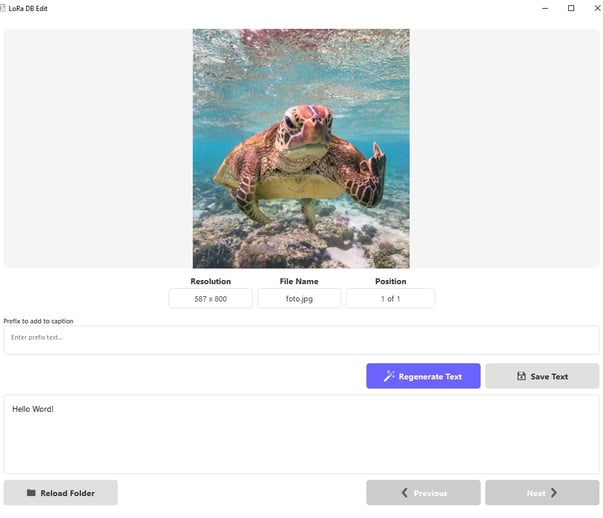
The trained model was integrated into the LoRaDBEdit software, which was updated to version 2.0 to simplify and optimize dataset management. This new version introduces several advanced features to improve the workflow.
LoRaDBEdit v2.0: New Features and Improvements


1. Integration of the LoraDBEdit_CaptionModel
• The trained AI model was optimized to create customized captions specific for LoRA Training.
• Caption generation takes about 13 seconds, with further optimizations in progress.
2. Space for Prefixes and Triggers
• A dedicated area was added to insert prefixes, trigger words, or other specific words to automatically add at the beginning of captions.
3. Improved Navigation
• Basic functionalities remain unchanged:
• Loading a dataset with images and texts.
• Simultaneous display of image and associated text.
• Navigation forward and backward between data.
• Displayed details:
• Image resolution.
• File name.
• Progressive number
• New Feature: Clicking on the progressive number (e.g., "1 of 200") opens a pop-up allowing you to directly select the desired image by entering the corresponding number.
4. New Buttons in the Text Section
• Regenerate Text: regenerates the existing description, creating a new caption with the LoraDBEdit_CaptionModel.
• Save Changes: saves the modifications made to the text associated with each image.
Basic Features
LoRaDBEdit continues to support:
• Loading datasets (images and texts).
• Simultaneous viewing of the image and associated text.
• Intuitive navigation between the data.
Conclusions
This workflow represents a concrete example of how advanced technical processes can lead to high-quality results. The integration of the LoraDBEdit_CaptionModel into LoRaDBEdit v2.0 has significantly improved dataset management, providing an efficient, customizable, and optimized environment for LoRA Training.
Note: The program is not yet available on GitHub as it is currently in the testing and optimization phase. We are working to improve its features and ensure the best possible experience before releasing it publicly.