

Test coerenza outfit e pose con Gemini
Nel corso di alcuni test sperimentali ho voluto mettere alla prova Gemini 2.0 Flash, un modello AI di generazione immagini, per verificarne la capacità di mantenere coerenza visiva tra elementi differenti dello stesso outfit, riprodurre pose realistiche e integrarsi in ambientazioni complesse.


Obbiettivo del test
Fase 1:
Ho diviso l'esperimento in più fasi. Nella prima, ho chiesto al modello di generare un outfit composto da maglietta, giacca e jeans, valutando quanto riuscisse a mantenere uno stile coerente tra i tre capi anche senza prompt dettagliati. I risultati sono stati sorprendentemente consistenti, anche senza indicazioni precise sulla texture o sulla palette cromatica.
Fase 2:
La seconda fase ha riguardato il contesto ambientale: ho provato a collocare il soggetto in location differenti (come Parigi e Santorini), testando se l’intelligenza artificiale fosse in grado di adattare luci, atmosfera e proporzioni architettoniche. Il risultato è stato un insieme di immagini credibili e visivamente armoniche, con una buona capacità di lettura dello scenario.


Fase 3:
Infine, ho voluto testare il controllo sulla posa del soggetto. Ho confrontato tre metodi di input:
Solo prompt + immagine del capo:
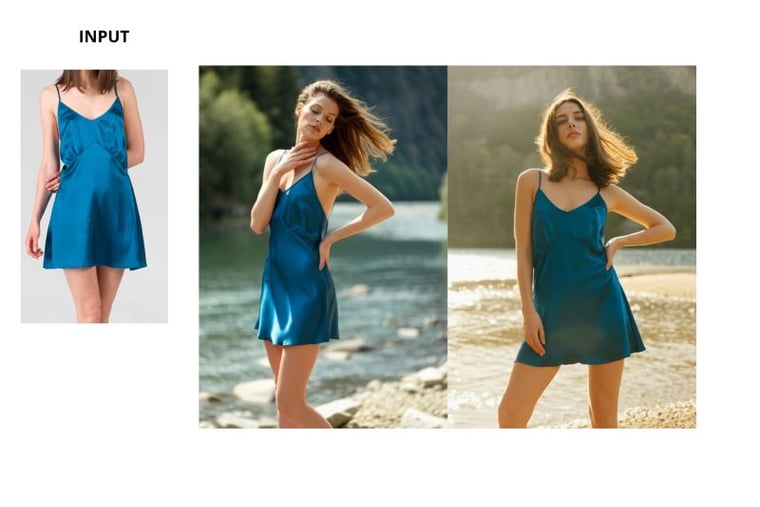
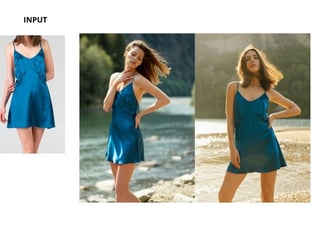
Prompt + immagine del capo + immagine di riferimento per la posa


Prompt + immagine del capo + immagine di riferimento + depth map


L’ultimo metodo ha mostrato i risultati più accurati nella riproduzione della posa, anche se è stato necessario generare più volte per ottenere un risultato pulito.
Questa sperimentazione rientra in una più ampia ricerca personale sull’uso dell’intelligenza artificiale nella moda e nei contenuti visivi. Gemini ha mostrato buone potenzialità in termini di consistenza tra outfit, integrazione ambientale e controllo della posa, anche se alcune variabili rimangono ancora parzialmente casuali.
CONTACT
info@lorenzomercugliano.com
© 2025. All rights reserved.
P.IVA 01593450115