

Training Personalizzato per Modelli di Testo
Questo workflow descrive il processo tecnico per creare e addestrare un modello di testo ottimizzato, il LoraDB Edit Caption Model, per generare caption personalizzate di alta qualità specifiche per il Training LoRA. Include inoltre l’integrazione del modello nel software LoRaDBEdit, con funzionalità avanzate per la gestione dei dataset.
Obiettivo
Fase 1: Creazione e Strutturazione del Dataset
Per garantire un training efficace, ho creato un dataset di 1080 immagini distribuite equamente tra diverse categorie per evitare squilibri e garantire una varietà sufficiente nei dati.
Distribuzione delle immagini:
Natura: 130 immagini
Città e Architettura: 120 immagini
Persone: 130 immagini
Animali: 130 immagini
Cibo e Bevande: 100 immagini
Tecnologia: 80 immagini
Moda e Stile: 70 immagini
Arte e Creatività: 70 immagini
Sport e Attività Fisiche: 50 immagini
Viaggi e Destinazioni: 50 immagini
Eventi e Celebrazioni: 20 immagini
Oggetti e Still Life: 150 immagini
Per ogni immagine, ho utilizzato Florence2Run per generare descrizioni dettagliate, che sono servite come base per creare caption personalizzate e specifiche per il Training LoRA.
Fase 2: Costruzione delle Caption
Dalle descrizioni iniziali, ho creato caption ad hoc per ogni immagine. Queste caption erano pensate per essere concise, descrittive e rilevanti, ottimizzando la capacità del modello di generare risposte contestualizzate.


Fase 3: Formattazione e Organizzazione del Dataset in CSV
Dopo aver creato tutte le caption, ho strutturato i dati in un file CSV con due colonne principali:
• User: Il prompt di input fornito dall’utente (descrizione generata).
• Prompt: La caption ad hoc creata per il Training LoRA (risultato ideale).
Fase di Pulizia e Formattazione
Rimozione dei dati duplicati: Ho eliminato eventuali descrizioni o caption duplicate che avrebbero potuto influire negativamente sul training.
Verifica di completezza: Ho controllato che ogni descrizione avesse una caption associata. In caso contrario, ho corretto manualmente le righe incomplete.
Formattazione coerente: Ho standardizzato il formato del testo, applicando regole come:
• Rimuovere spazi superflui all’inizio o alla fine del testo.
• Utilizzare lettere maiuscole per iniziare ogni frase.
• Aggiungere la punteggiatura mancante (es. punti finali).
Conversione del dataset: Ho salvato il dataset in formato CSV, garantendo compatibilità con le librerie utilizzate durante il training.
Preparazione per l’Addestramento
Prima dell’addestramento, ho convertito il dataset in una struttura JSON per renderlo compatibile con il formato richiesto dal modello:




Il training è stato eseguito utilizzando il modello LLaMA 3.2, con 14 miliardi di parametri, sfruttando librerie come Torch per la gestione e il caricamento del modello.
Tecniche Utilizzate
• LoRA (Low-Rank Adaptation): Ho utilizzato questa tecnica per aggiungere solo un piccolo numero di pesi al modello principale, riducendo tempi e costi di calcolo.
• Monitoraggio della Training Loss: Ho tracciato la diminuzione della loss durante il training, verificando che scendesse da valori elevati (es. 2.89) a valori bassi (es. 0.89), segno di un apprendimento efficace.
Il risultato è stato il LoraDB Edit Caption Model, capace di generare autonomamente caption ottimizzate per il Training LoRA.
Fase 4: Training del Modello
Dopo aver eseguito il training, ho osservato un netto miglioramento nelle risposte del modello. Inizialmente, il modello tendeva a generare risposte vaghe o poco contestualizzate. Ecco un esempio di confronto tra le risposte prima e dopo l'addestramento:
Fase 5: Confronto Prima e Dopo l'Addestramento
Prima dell'addestramento:
Dopo l'addestramento (con il nuovo modello):
Questo miglioramento mostra come l'addestramento abbia permesso al modello di produrre risposte più accurate, descrittive e contestualizzate, ottimizzando la generazione delle caption ad hoc per il Training LoRA.




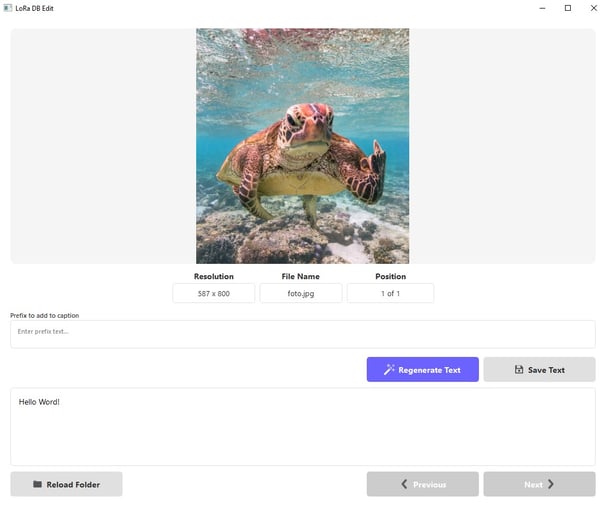
Fase 6: Integrazione del Modello in LoRaDBEdit
Il modello addestrato è stato integrato nel software LoRaDBEdit, che è stato aggiornato alla versione 2.0 per semplificare e ottimizzare la gestione dei dataset. Questa nuova versione introduce diverse funzionalità avanzate per migliorare il flusso di lavoro.
LoRaDBEdit v2.0: Novità e Miglioramenti
1. Integrazione del Modello LoraDBEdit_CaptionModel
• Il modello AI addestrato è stato ottimizzato per creare caption ad hoc specifiche per il Training LoRA.
• La generazione delle caption richiede circa 13 secondi, con ulteriori ottimizzazioni in corso.
2. Spazio per Prefissi e Trigger
• È stata aggiunta un’area dedicata per inserire prefissi, parole trigger o altre parole specifiche da aggiungere automaticamente all’inizio delle caption.
3. Navigazione Migliorata
• Le funzionalità base rimangono intatte:
• Caricamento di un dataset con immagini e testi.
• Visualizzazione simultanea di immagine e testo associato.
• Navigazione avanti e indietro tra i dati.
• Dettagli visualizzati:
• Risoluzione dell’immagine.
• Nome del file.
• Numero progressivo
• Nuova funzionalità: cliccando sul numero progressivo (es. “1 di 200”), appare un pop-up che consente di selezionare direttamente l’immagine desiderata inserendo il numero corrispondente.
4. Nuovi Bottoni nella Sezione Testo
• Regenerate Text: rigenera la descrizione esistente, creando una nuova caption con il modello LoraDBEdit_CaptionModel.
• Save Changes: salva le modifiche apportate al testo associato a ciascuna immagine.
Funzionalità Base
LoRaDBEdit continua a supportare:
• Caricamento di dataset (immagini e testi).
• Visione simultanea dell’immagine e del testo associato.
• Navigazione intuitiva tra i dati.
Conclusioni
Questo workflow rappresenta un esempio concreto di come processi tecnici avanzati possano portare a risultati di alta qualità. L’integrazione del modello LoraDBEdit_CaptionModel in LoRaDBEdit v2.0 ha migliorato significativamente la gestione dei dataset, fornendo un ambiente efficiente, personalizzabile e ottimizzato per il Training LoRA.


Nota: Il programma non è ancora disponibile su GitHub in quanto è attualmente in fase di test e ottimizzazione. Stiamo lavorando per migliorare le funzionalità e garantire la migliore esperienza possibile prima di renderlo pubblico.
CONTACT
info@lorenzomercugliano.com
© 2025. All rights reserved.
P.IVA 01593450115